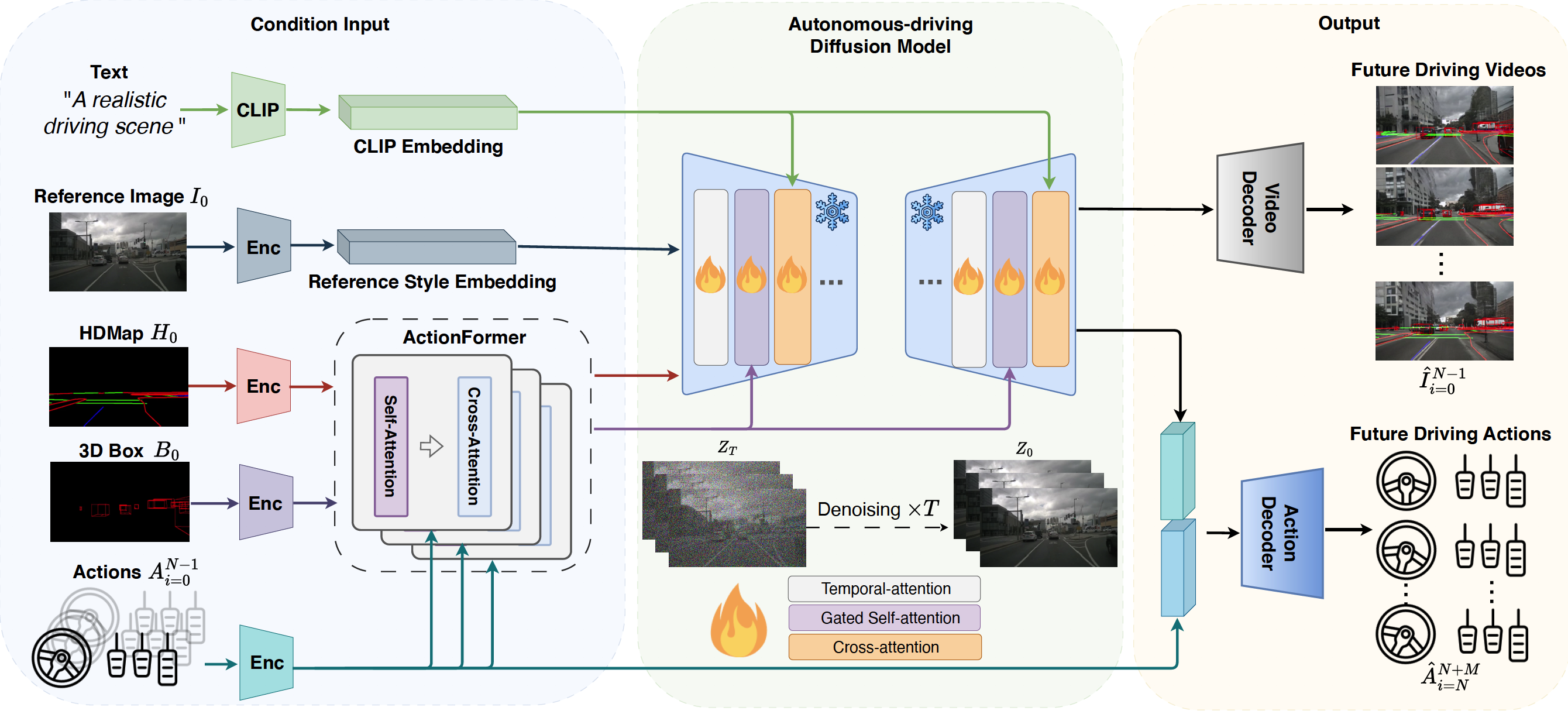
World models, especially in autonomous driving, are trending and drawing extensive attention due to its
capacity for comprehending driving environments. The established world model holds immense potential
for the generation of high-quality driving videos, and driving policies for safe maneuvering. However,
a critical limitation in relevant research lies in its predominant focus on gaming environments or simulated
settings, thereby lacking the representation of real-world driving scenarios. Therefore, we introduce
DriveDreamer, a pioneering world model entirely derived from real-world driving scenarios. Regarding that
modeling the world in intricate driving scenes entails an overwhelming search space, we propose harnessing
the powerful diffusion model to construct a comprehensive representation of the complex environment. Furthermore,
we introduce a two-stage training pipeline. In the initial phase, DriveDreamer acquires a deep understanding of
structured traffic constraints, while the subsequent stage equips it with the ability to anticipate future states.
The proposed DriveDreamer is the first world model established from real-world driving scenarios. We instantiate
DriveDreamer on the challenging nuScenes benchmark, and extensive experiments verify that DriveDreamer empowers precise,
controllable video generation that faithfully captures the structural constraints of real-world traffic scenarios.
Additionally, DriveDreamer enables the generation of realistic and reasonable driving policies, opening avenues for
interaction and practical applications.